Definiując
noSQL warto zaznaczyć, że nie chodzi tutaj o niniejszy jakiś żart. O ile specjaliści od T-SQL i posiadacze stu certyfikatów ORACLE myślą inaczej, są rekomendacje płynące chociażby z digg.com, facebook.com, yahoo,com ale od zawsze z google.com potwierdzające, że
trend noSQL ma sens w przetwarzaniu i składowaniu dużej ilości danych. Mając na myśli dużej mam na myśli setki Gigabahjtów, Terabajty i Petabajty ... i nie jest to wcale SF :-) Problem jak zwykle dotyczy skali i oczywiście dotyczy grupowania i złączania danych z różnych źródeł i baz. Tutaj składnia ... JOIN ... może okazać się nieco zasobożerna i nie na miejscu ;-) W miejsce, gdzie nie można robić SELECT i LIMIT + OFFSET + JOIN lub zwyczajne zapytania wykonują się zbyt długo, a CRON + memcached nie wystarczy potrzebne są bazy danych noSQL do składowania i mechanizmy Map Reduce do agregacji i łączenia danych dla osiągnięcia pożądanych wyników. Oczywiście że nie istnieje jedna baza do wszystkich zastosowań ... oto
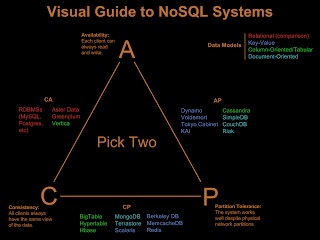
pomocnik w wyborze bazy noSQL.
Od 2001 roku, od kiedy to przyszło mi korzystać produkcyjne z bazy danych mySQL nie miałem pojęcia, że używam idei
noSQL. Moja baza danych to było składowisko danych pomiarowych z różnej maści mierników elektronicznych oraz różnego typu alarmów, przy przekraczaniu zakresów. Napisałem wspólnie z kolegą z zespołu sterownik do składowania danych binarnie, ale z ideą podobną jak
DBASE IV. Okazało się, że silnik i sterownik naszej bazy świetnie się sprawdzał i działał zgodnie z założeniami w wielowątkowym środowisku. Jednak potrzeba przetwarzania danych zmusiła mnie do przechowywania danych w bazie SQL, aby wykonywać prościej rankingi na danych. Wówczas ideę złączeń należało po prostu odrzućić ... nie będę tłumaczył powodów, dla których mySQL 3.28.x się wtedy zamulał przy złożonych JOINach ;-) Ważne, że założenie to było słuszne jak na rok 2001 i
PHP 3.x.
Patrząc z perspektywy czasu uświadomiłem sobie, że utworzyłem w mySQL coś takiego jak mój własny
noSQL. Składowałem dane w kolumnach, ale również utworzyłem superkolumny z pól tekstowych, w które wpisywałem oddzielone identyfikatorami wartości powiązanych danych. Dane były wiązane we wręcz prostacki sposób, ale taka metoda pozwalała - zamiast stosowania JOINów - przetwarzanie źródłowych danych z pomiarów do postaci pośredniej przez 6h a nie 11h. Jak na tamte czasy i koszty hostingu/dedykowanych serwerów było to znacząco optymalne podejście.
Współcześnie widzę trend dość podobny (z ang.
structured storage) i równie banalny w zastosowaniu tzn. używanie "superkolumn" w składowaniu danych w ramach tej samej kolumny. Dodawanie zamiast relacji niejako "nadmiarowych" i zarazem powiązanych danych w wierszu, które podlegają wydajniejszemu wyszukiwaniu niżeli tradycyjne metody z baz SQL. Nie zawsze mogą konkurować z zewnętrznym indeksem opartym na rozwiązaniu t.j.
Apache Lucene.
Rozwiązań serwujących ideę
noSQL jest sporo i po pełną listę zapraszam do odpowiedniego źródła, któro porównuje i próbuje skatalogować
bazy danych noSQL.











